System Architecture
VantEdge provides an intelligent deployment architecture that separates the control plane from your data plane, ensuring complete data isolation while providing centralized management.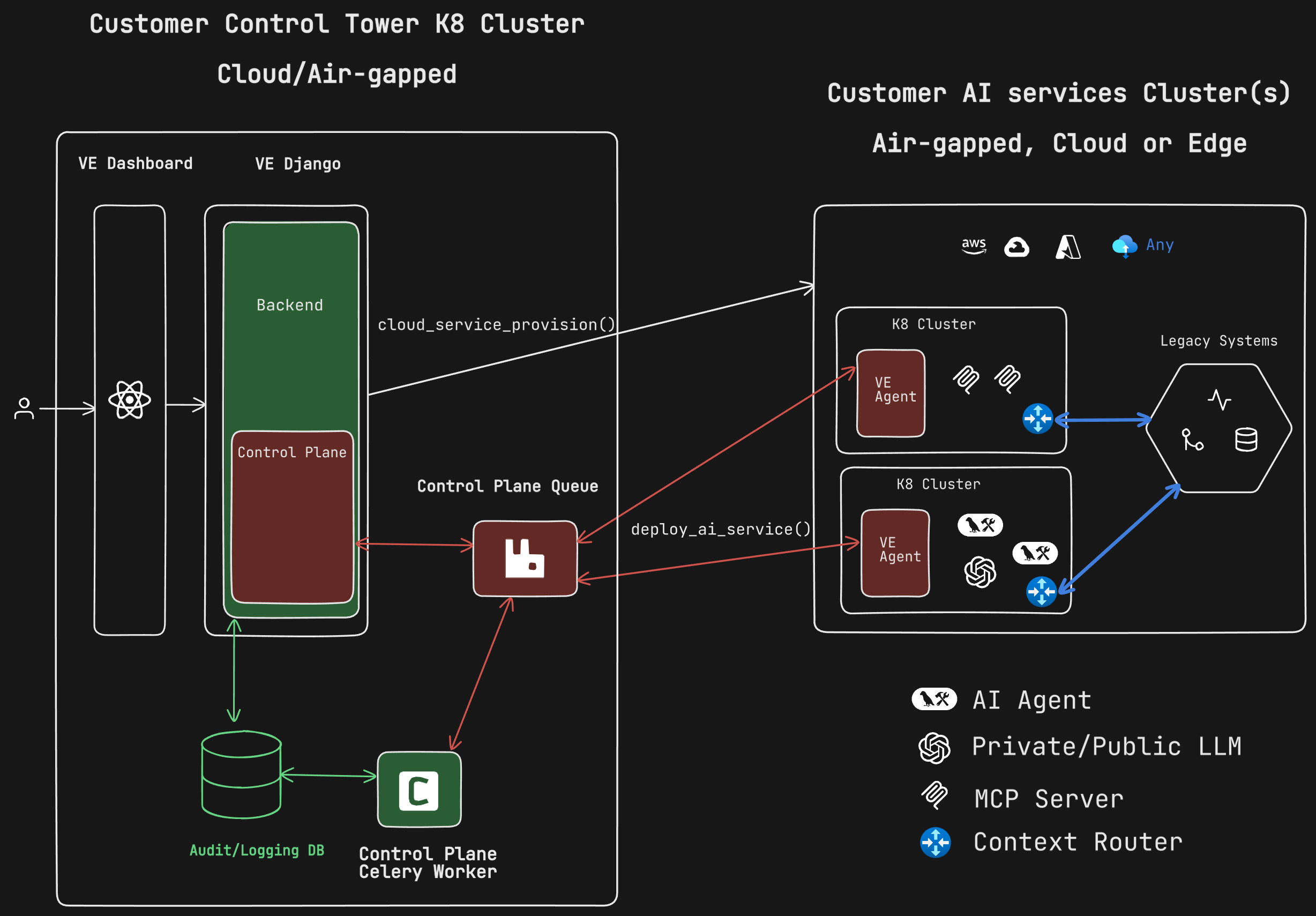
Architecture Components
Control Plane (VantEdge Infrastructure)
The control plane is hosted VantEdge infrastructure that handles orchestration and deployment workflows: Key components:- VE Dashboard + Backend: Web interface and API for managing deployments
- Control Plane Queue: Asynchronous task queue (Celery) handling deployment requests with retry logic
- Audit/Logging DB: Complete audit trail of all deployment activities and system events
cloud_service_provision()- Provisions infrastructure resourcesdeploy_ai_service()- Deploys AI agents and models
Data Plane (Customer Infrastructure)
Your data and workloads remain in your infrastructure with complete isolation: VE Agents: Lightweight agents deployed in your Kubernetes clusters that:- Execute deployment commands from the control plane
- Report status and metrics back to control plane
- Run alongside your AI workloads
- Access your data sources directly
- Run in containerized environments
- Access your databases and data sources
- Process data locally without sending to VantEdge
- Maintain sub-100ms latency through data locality
Integration Layer
VantEdge connects with your existing infrastructure: Legacy Systems- PostgreSQL databases
- MongoDB and NoSQL stores
- S3 data lakes
- On-premises data sources
- Slack, Gmail, Microsoft Teams
- Salesforce, HubSpot
- Jira, Asana, Linear
- Google Drive, Notion, Confluence
Data Locality & Performance
The architecture enables intelligent, data-aware deployment:- Sub-100ms latency for data access operations
- Reduced egress costs by minimizing cross-region data transfers
- Improved reliability through local data availability
- Better compliance with data residency requirements
Intelligent Orchestration
The deployment system analyzes workload requirements and determines optimal placement: Analysis Factors:- CPU, memory, and GPU requirements
- Data access patterns and frequency
- Network latency requirements
- Data residency and compliance needs
- Lifecycle management (scaling, updates, recovery)
- Dynamic resource adjustment based on usage
- Health monitoring and automatic failover
- Zero-downtime rolling updates
Security & Isolation
Complete Data Isolation- Your data never leaves your infrastructure
- VantEdge control plane only manages orchestration
- No data flows through VantEdge systems
- Encrypted channels between control plane and VE Agents
- RBAC for deployment permissions
- Secrets management for credentials
- Audit logging for all operations
This architecture enables VantEdge to provide centralized management and intelligent orchestration while keeping your data secure and isolated in your own infrastructure.